Engelmann and Carnine's Theory of Instruction has a reputation for being somewhat inaccessible to many who attempt to read it. It's big, it's long, quite a number of examples are maths related, and lastly (and probably most crucially) they use their own terminology when referring to specific ideas.
Over the past few years in particular, a number of ideas from Cognitive Load Theory have become more widely known and the terminology used has spread further. What I've found from reading Oliver Lovell's book Sweller's Cognitive Load Theory in Action is that a number of the ideas in Theory of Instruction relate back to the ideas in Cognitive Load Theory. That creates an opportunity, where the ideas in Theory of Instruction can be linked to ideas in Cognitive Load Theory to create a more widely shared vocabulary. Below I've used quotes from Ollie's book to compare Cognitive Load Theory with Engelmann and Carnine's Theory of Instruction.
Over the past few years in particular, a number of ideas from Cognitive Load Theory have become more widely known and the terminology used has spread further. What I've found from reading Oliver Lovell's book Sweller's Cognitive Load Theory in Action is that a number of the ideas in Theory of Instruction relate back to the ideas in Cognitive Load Theory. That creates an opportunity, where the ideas in Theory of Instruction can be linked to ideas in Cognitive Load Theory to create a more widely shared vocabulary. Below I've used quotes from Ollie's book to compare Cognitive Load Theory with Engelmann and Carnine's Theory of Instruction.

That being said, while some ideas from Theory of Instruction are minimally different from ideas in Cognitive Load Theory, others are related but not close enough to warrant calling them the same thing, and still others I have not found a direct connection between. So let this blogpost be a starting point for creating a common vocabulary between Theory of Instruction, Cognitive Load Theory, and other well-known ideas.
The Expertise-Reversal Effect
"The expertise-reversal effect suggests that learners need differing amounts of support depending on their level of expertise. In fact, the instructional recommendations that Cognitive Load Theory provides for more novice and more expert students are often reversed." (Lovell, 2020, p58)
Keep in mind that expertise is domain-specific and depends upon the knowledge stored in long-term memory that's relevant to a given domain. So a student that is an expert in a specific domain, sub-domain of knowledge, or skill, may not be an expert in another.
"Novice students lack an understanding of how certain problems should be approached, and therefore benefit from worked examples, which provide a high level of guidance and structure. Worked examples can be redundant for more expert students, who likely already understand how the problem should be solved. They therefore benefit more from practice rather than examples of problem solving. Problem solving provides practice that these more expert students need to automate their skills. However, it provides insufficient support for novices who don't as yet understand the underlying principles." (Lovell, 2020, p58)
"Knowledge of boundary conditions is crucial because, without it, we're likely to apply an instructional strategy in an unsuitable context, or in an unsuitable way, leading to reduced learning." (Lovell, 2020, p58)
Theory of Instruction often refers to novice and facile learners in the same way Cognitive Load Theory refers to novices and experts. Whether we work with the novice learner or the facile learner, what is taught must be used and it must be applied to new contexts.
Structuring and Persisting with Worked Examples
Construct worked examples to minimise extraneous load. "A badly structured worked example presented to learners may be no more effective or even less effective than solving the equivalent problem. If extraneous cognitive load is not reduced compared to problem solving, the use of worked examples will not be effective." (Sweller, Ayres, & Kalyuga 2011 in Lovell, 2020, p107)
"Continue to work with worked examples for far longer than traditionally deemed necessary" (Lovell, 2020, p107). "It may be beneficial to persist with examples until complete familiarity with the material is attained." (Sweller & Cooper 1985 in Lovell, 2020, p107)
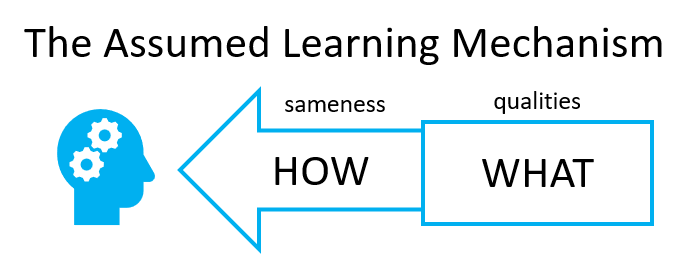
Theory of Instruction takes a teacher-centric position for instruction (chapter 1). It assumes that the primary cause of students not learning a concept is because the communication was faulty in some way. It introduces the concept of faultless communication that is designed to convey only one interpretation given any requisite knowledge. The communication is judged faultless if it adequately provides the learner with information about quality and sameness.
The primary problem that we face in pursuing this strategy is that we do not know what constitutes a faultless communication unless we make some assumptions about the learner. The greater the assumed capabilities of the learner, the less the assumed responsibility of the communication. We start with analysing the communication rather than the student to rule it out if the problem persists.
Engelmann builds his ideas of faultless communication on an assumed learning mechanism with two attributes:
The Expertise-Reversal Effect
"The expertise-reversal effect suggests that learners need differing amounts of support depending on their level of expertise. In fact, the instructional recommendations that Cognitive Load Theory provides for more novice and more expert students are often reversed." (Lovell, 2020, p58)
Keep in mind that expertise is domain-specific and depends upon the knowledge stored in long-term memory that's relevant to a given domain. So a student that is an expert in a specific domain, sub-domain of knowledge, or skill, may not be an expert in another.
"Novice students lack an understanding of how certain problems should be approached, and therefore benefit from worked examples, which provide a high level of guidance and structure. Worked examples can be redundant for more expert students, who likely already understand how the problem should be solved. They therefore benefit more from practice rather than examples of problem solving. Problem solving provides practice that these more expert students need to automate their skills. However, it provides insufficient support for novices who don't as yet understand the underlying principles." (Lovell, 2020, p58)
"Knowledge of boundary conditions is crucial because, without it, we're likely to apply an instructional strategy in an unsuitable context, or in an unsuitable way, leading to reduced learning." (Lovell, 2020, p58)
Theory of Instruction often refers to novice and facile learners in the same way Cognitive Load Theory refers to novices and experts. Whether we work with the novice learner or the facile learner, what is taught must be used and it must be applied to new contexts.
Structuring and Persisting with Worked Examples
Construct worked examples to minimise extraneous load. "A badly structured worked example presented to learners may be no more effective or even less effective than solving the equivalent problem. If extraneous cognitive load is not reduced compared to problem solving, the use of worked examples will not be effective." (Sweller, Ayres, & Kalyuga 2011 in Lovell, 2020, p107)
"Continue to work with worked examples for far longer than traditionally deemed necessary" (Lovell, 2020, p107). "It may be beneficial to persist with examples until complete familiarity with the material is attained." (Sweller & Cooper 1985 in Lovell, 2020, p107)
Theory of Instruction takes a teacher-centric position for instruction (chapter 1). It assumes that the primary cause of students not learning a concept is because the communication was faulty in some way. It introduces the concept of faultless communication that is designed to convey only one interpretation given any requisite knowledge. The communication is judged faultless if it adequately provides the learner with information about quality and sameness.
The primary problem that we face in pursuing this strategy is that we do not know what constitutes a faultless communication unless we make some assumptions about the learner. The greater the assumed capabilities of the learner, the less the assumed responsibility of the communication. We start with analysing the communication rather than the student to rule it out if the problem persists.
Engelmann builds his ideas of faultless communication on an assumed learning mechanism with two attributes:
- the capacity to learn any quality that is exemplified through examples.
- the capacity to generalise to new examples on the basis of sameness of quality (and only on the basis of sameness).
If a learner does not perform in the predicted manner, we immediately know three things about that learner:
Faultless communication rests on the following structural conditions:
- We know that the learner does not have (or is not using) the two-attribute mechanism.
- We know the precise ways that the learner’s performance deviated from the predicted performance.
- Because we know that the problem resides with the learner and not with the communication (which is judged faultless), and because we know precisely how the learner has deviated from the predicted standard, we know how we must modify the learner so that the learner is capable of performing acceptably in response to the communication.
Faultless communication rests on the following structural conditions:
- The positive examples of the concept must be distinguished by one and only one quality.
- An unambiguous signal must accompany each positive example, and a different signal must accompany each negative example.
- The examples must demonstrate the range of variation to which the learner will be expected to generalise.
- Negative examples must clearly show the boundaries of permissible positive variation.
- Test examples, different from those presented to demonstrate the concept, assure that the generalization has occurred.

Following these are the operations to induce generalisations which explain what is likely inferred from the set of examples we choose (chapter 2).
Further iterating on this are the facts about presenting examples (chapter 4):
And the juxtaposition principles (chapter 4):
- Interpolation: if the range of variation shown by obviously different examples does not cause the label to change, an intermediate value or change should also be treated in the same way. Therefore, using greatly different examples that are treated the same allows for greater interpolation.
- Extrapolation: if the change from a given positive example to a minimally different negative causes the negative to be labelled differently, a greater change in the same direction from the positive will also result in a negative example. The use of a minimally different example allows the line between an example and non-example to be drawn more clearly when they are treated differently.
- Stipulation: repeated presentation of examples that have a great many samenesses implies that all features of these examples are necessary to the label. Stipulation can be a good and bad thing depending on context. While stipulation helps to show sameness, if examples are not chosen well misconceptions (or misrules) can be formed. For example, if polygons are only drawn as regular with equal side lengths and angles, then irregular polygons may not be correctly classified because they don't look the same.
Further iterating on this are the facts about presenting examples (chapter 4):
- It is impossible to teach a concept through the presentation of one example. That is, one example is not enough to know what features are specific to this concept. Use multiple examples.
- Any sameness shared by both positive and negative examples rules out a possible interpretation. That is, features shared by examples and non-examples cannot be the reason why one is a negative example.
- It is impossible to present a group of positive examples that communicates only one interpretation. That is, a group of examples may share other similarities than the intended concept. Using non-examples rules out common features to both as possible interpretations.
- A negative example rules out the maximum number of interpretations when the negative example is least different from some positive example. Use minimum differences between examples and non-examples.
And the juxtaposition principles (chapter 4):
- Wording Principle: To make the sequence of examples as clear as possible, use the same wording on juxtaposed examples (or wording that is as similar as possible).
- Setup Principle: To minimise the number of examples needed to demonstrate a concept, juxtapose examples that share the greatest possible number of features.
- Difference Principle: To show differences between examples, juxtapose examples that are minimally different and treat the examples differently.
- Sameness Principle: To show samenesses across examples, juxtapose examples that are greatly different and indicate that the examples have the same label.
- Testing Principle: To test the learner, juxtapose examples that bear no predictable relationship to each other. Test immediately after presenting.
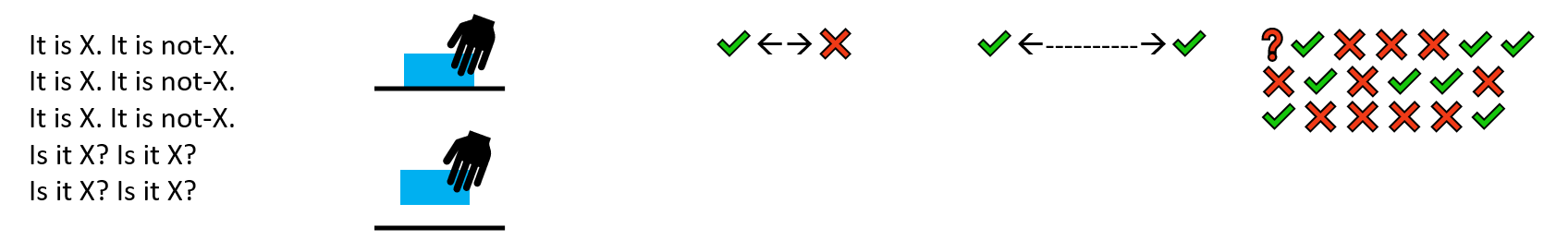
Pre-Teaching
'Trying to learn new skills in tandem with applying them to a new scenario will lead to a very high intrinsic load." (Lovell, 2020, p43) "Delivering a portion of the content before the main lesson, and reinforcing it through revision over time, can reduce the intrinsic load experience by students when they attempt the final, complete task." (Lovell, 2020, p39) Novices in a skill will learn content that requires the application of that skill more effectively if the relevant skill is learned prior to attempting to learn the content. "Novices will experience lower intrinsic load if the skill is taught prior to the requirement to apply it to challenging content." (Lovell, 2020, p44)
Pre-teaching is at the heart of mastery teaching, such that you can't achieve mastery if you introduce tasks that are far beyond the learner's ability, and if you don't give kids enough practice (Clear Teaching). Engelmann advocates for at most 15% new material and 85% reinforcement of things already taught in a given lesson.
We want to identify all skills that go into performing a task, arrange them into a logical sequence, then lay out instruction to ensure students get enough practice to master each new concept or skill.
Everything learned is applied over and over and in different contexts and seemingly isolated skills are taught and combined with other skills to teach more complex skills. This is, in part, why "fast learners” are fast: because they have less to learn. That is, they have been pre-taught, either intentionally or unintentionally, the skills and knowledge to be able to connect new ideas to old ones secured in long-term memory compared to "slower learners" that are required to learn both the new ideas and the old ones their faster counterparts have already learned.
That being said, we need to keep in mind the following points:
Segmenting, Atomising, and the Isolated Elements Effect
The isolated elements effect states that "intrinsic cognitive load can be reduced by breaking up a task into bite-sized chunks." (Lovell, 2020, p44) These segments or atoms of a task can be pre-taught prior to the task to reduce intrinsic cognitive load. By isolating an atom, we cut down on element interactivity between the atoms.
"For complex skills, student practice of a segmented skill often looks very different from the final performance." "Effective segmentation for complex skills often requires practising a diversity of tasks that support, rather than directly underpin, the final performance." (Lovell, 2020, p47)
A cognitive routine is a series of steps that solves any problem of a given type. It consists of a series of more than two steps (questions or instructions), where components are pre-taught and requires the learner to produce overt responses to these steps.
The individual components for a routine are scheduled (chapter 19) as coordinate members of set (chapters 10 & 11) such that:
For routines with condition parts (chapter 19), where the learner must make a choice that determines how the routine proceeds, we can break down the practice:
The key discrimination between routes works as a correlated-feature relationship: if X, then Y or if A, then B.
Chunking
"Humans draw upon the environment (external and unlimited), long-term memory (internal and unlimited), and working memory (internal and limited) in order to think." (Lovell, 2020, p19) Since working memory is limited, it can be overwhelmed with new information that is not in long-term memory if the element interactivity is high (it is numerous in pieces of information or interactions between pieces of information).
To overcome these limits of our working memory, we chunk and automate information. Chunking is "the process of combining multiple smaller elements into a single larger element within long-term memory" where recall of the larger element from "long-term memory becomes automatic and effortless." (Lovell, 2020, p20)
Covertisation (chapter 21) is the process of replacing the highly overtised routine with less structured routines. That is, after making every step in a sequence explicit or overt, gradually making many or most of them implicit or covert.
Like chunking, covertisation aims to segment a process into larger and larger chunks so they can be processed together as a singular unit. This can be done by:
'Trying to learn new skills in tandem with applying them to a new scenario will lead to a very high intrinsic load." (Lovell, 2020, p43) "Delivering a portion of the content before the main lesson, and reinforcing it through revision over time, can reduce the intrinsic load experience by students when they attempt the final, complete task." (Lovell, 2020, p39) Novices in a skill will learn content that requires the application of that skill more effectively if the relevant skill is learned prior to attempting to learn the content. "Novices will experience lower intrinsic load if the skill is taught prior to the requirement to apply it to challenging content." (Lovell, 2020, p44)
Pre-teaching is at the heart of mastery teaching, such that you can't achieve mastery if you introduce tasks that are far beyond the learner's ability, and if you don't give kids enough practice (Clear Teaching). Engelmann advocates for at most 15% new material and 85% reinforcement of things already taught in a given lesson.
We want to identify all skills that go into performing a task, arrange them into a logical sequence, then lay out instruction to ensure students get enough practice to master each new concept or skill.
Everything learned is applied over and over and in different contexts and seemingly isolated skills are taught and combined with other skills to teach more complex skills. This is, in part, why "fast learners” are fast: because they have less to learn. That is, they have been pre-taught, either intentionally or unintentionally, the skills and knowledge to be able to connect new ideas to old ones secured in long-term memory compared to "slower learners" that are required to learn both the new ideas and the old ones their faster counterparts have already learned.
That being said, we need to keep in mind the following points:
- we need to start as close as possible to where the learner performs
- our first attempt should be to teach the total operation without teaching parts.
Segmenting, Atomising, and the Isolated Elements Effect
The isolated elements effect states that "intrinsic cognitive load can be reduced by breaking up a task into bite-sized chunks." (Lovell, 2020, p44) These segments or atoms of a task can be pre-taught prior to the task to reduce intrinsic cognitive load. By isolating an atom, we cut down on element interactivity between the atoms.
"For complex skills, student practice of a segmented skill often looks very different from the final performance." "Effective segmentation for complex skills often requires practising a diversity of tasks that support, rather than directly underpin, the final performance." (Lovell, 2020, p47)
A cognitive routine is a series of steps that solves any problem of a given type. It consists of a series of more than two steps (questions or instructions), where components are pre-taught and requires the learner to produce overt responses to these steps.
The individual components for a routine are scheduled (chapter 19) as coordinate members of set (chapters 10 & 11) such that:
- we separate highly similar members and avoid juxtaposing minimum-differences
- more practice is given to skills that require difficult discriminations or responses
- each skill must be introduced, expanded, and reviewed.
- we provide for the firming of each component skill.
For routines with condition parts (chapter 19), where the learner must make a choice that determines how the routine proceeds, we can break down the practice:
- firm the non-conditional routine first (without over stipulating that route)
- introduce and firm the conditional part while expanding and reviewing the non-conditional routine
- work on the discrimination that decides which contingency is chosen (positive/negative first sequence)
- chain a shortened version of the original routine with the discrimination and the contingent part
- finally, integrate problems that are conditional and non-conditional.
The key discrimination between routes works as a correlated-feature relationship: if X, then Y or if A, then B.
Chunking
"Humans draw upon the environment (external and unlimited), long-term memory (internal and unlimited), and working memory (internal and limited) in order to think." (Lovell, 2020, p19) Since working memory is limited, it can be overwhelmed with new information that is not in long-term memory if the element interactivity is high (it is numerous in pieces of information or interactions between pieces of information).
To overcome these limits of our working memory, we chunk and automate information. Chunking is "the process of combining multiple smaller elements into a single larger element within long-term memory" where recall of the larger element from "long-term memory becomes automatic and effortless." (Lovell, 2020, p20)
Covertisation (chapter 21) is the process of replacing the highly overtised routine with less structured routines. That is, after making every step in a sequence explicit or overt, gradually making many or most of them implicit or covert.
Like chunking, covertisation aims to segment a process into larger and larger chunks so they can be processed together as a singular unit. This can be done by:
- dropping steps that are not critical with facility, are awkward, parts of a chain, or mechanical details
- regrouping steps that lead to the same goal or steps that always occur in a fixed order (also referred to as scheduling clusters (chapter 19))
- replacing a series of specific instructions with one inclusive instruction with less detail but still induces the same behaviour.

The following instructions are given in Theory of Instruction with regard to covertisation:
Interleaving
Interleaving, as opposed to blocking similar problems, mixes problems that require different solutions. Interleaving helps learners to identify differences in situations where they have traditionally been confused by similarities. That is, interleaving helps students to learn "which method or formula is appropriate for different situations" (Lovell, 2020, p56) rather than learn how to use a specific method or formula by providing "students with a greater opportunity to compare and contrast those elements, and to therefore build stronger connections." (Lovell, 2020, p55)
"If problems are positioned next to each other in time and require the same set of skills for solution, then contextual interference is low. If problems are positioned next to each other are require a different set of skills then contextual interference is high." (Sweller, Ayres, & Kalyuga 2011 in Lovell, 2020, p55)
"While research has confirmed that students are likely to complete the work quicker under blocked conditions, and achieve more correct answers during practice, it won't prepare them as well for future scenarios in which they have to independently choose which tense to use, and how to apply it correctly." (Lovell, 2020, p57)
"The key danger with interleaving is progressing to interleaved examples too early. It's imperative that students can do each of the processes in isolation prior to them being interleaved." (Lovell, 2020, p57)
To help students who can produce a particular response, but not in context of a task or does not associate a particular response with the signal or cue, we can use context-shaping (the three level strategy) to teach when to produce responses where we systematically provide interruptions of the task being taught (chapter 22):
When a student performs accurately on four consecutive trials they move up one level. If a mistake is made, the student moves back to level one, but only need to perform accurately on two consecutive trials on the level(s) they have already passed.
- Retain each successive, partially-faded routine for at least two days or lessons.
- Process at least two examples through the routine each time it appears.
- Do not change more than 30% of the preceding routine.
- Do not change more than 50% for experienced learners or short routines (8 or fewer steps).
- Keep the covertisation process as simple as possible.
Interleaving
Interleaving, as opposed to blocking similar problems, mixes problems that require different solutions. Interleaving helps learners to identify differences in situations where they have traditionally been confused by similarities. That is, interleaving helps students to learn "which method or formula is appropriate for different situations" (Lovell, 2020, p56) rather than learn how to use a specific method or formula by providing "students with a greater opportunity to compare and contrast those elements, and to therefore build stronger connections." (Lovell, 2020, p55)
"If problems are positioned next to each other in time and require the same set of skills for solution, then contextual interference is low. If problems are positioned next to each other are require a different set of skills then contextual interference is high." (Sweller, Ayres, & Kalyuga 2011 in Lovell, 2020, p55)
"While research has confirmed that students are likely to complete the work quicker under blocked conditions, and achieve more correct answers during practice, it won't prepare them as well for future scenarios in which they have to independently choose which tense to use, and how to apply it correctly." (Lovell, 2020, p57)
"The key danger with interleaving is progressing to interleaved examples too early. It's imperative that students can do each of the processes in isolation prior to them being interleaved." (Lovell, 2020, p57)
To help students who can produce a particular response, but not in context of a task or does not associate a particular response with the signal or cue, we can use context-shaping (the three level strategy) to teach when to produce responses where we systematically provide interruptions of the task being taught (chapter 22):
- Level 1: Repeat the task.
- Level 2: Interleave one familiar task.
- Level 3: Interleave three familiar tasks.
When a student performs accurately on four consecutive trials they move up one level. If a mistake is made, the student moves back to level one, but only need to perform accurately on two consecutive trials on the level(s) they have already passed.
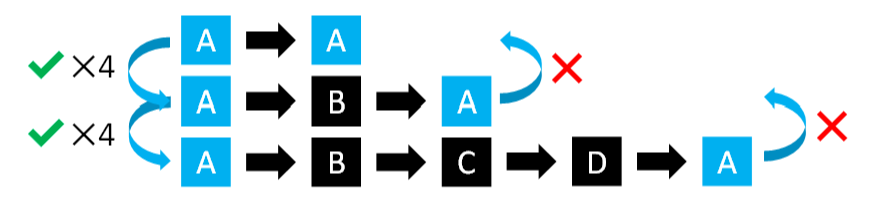
After level 3, we move the student onto integration activities. Context integration tests progressively harder sequences of the new item with familiar tasks starting with items that are greatly different moving towards sequences that are highly similar. Each sequence should be firmed before moving onto the next, more similar, sequence.
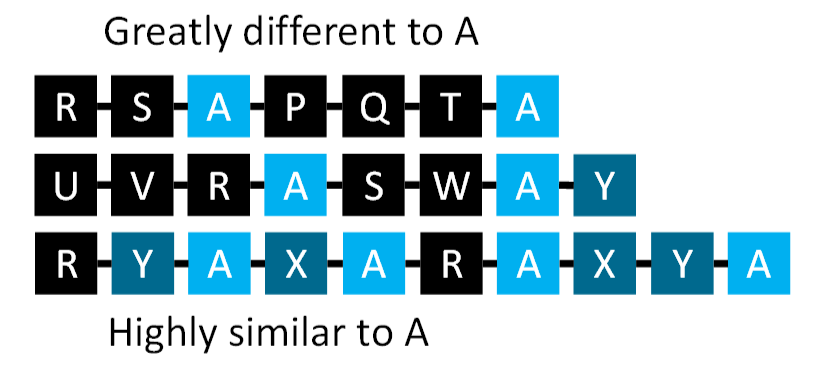
Where students still struggle to identify the relevant features to distinguish between one response and another, a prompt can be introduced. A prompt is a detail added to an example so relevant features are more obvious than when unprompted. A prompt is used only for initial teaching and is then removed. They provide details that increase differences (chapter 20). There are different types of prompts:
There is no prompt that is “correct.” A prompt serves a need. If it is constructed according to the appropriate procedures, it will serve the need.
When transitioning to unprompted examples:
Manipulate the Emphasis
"Having students focus on just a few key portions of a task is a powerful tool for reducing intrinsic load, especially in the early stages of integrating a new skill into an existing process." That is, telling students "I won't worry about this, so you can focus on that." (Lovell, 2020, p54)
When a student knows what they need to do, just not how to do it or at the desired accuracy rate, we can use response-shaping by reinforcing on progressively better approximation responses to shape the response into the desired response (chapter 22).
Response shaping follows this process:
- difference prompts that are a simple transformation of the features that are relevant to the discrimination to draw attention to the difference to make it easier to identify and determine what to do in the each case
- sameness prompts that introduce details that will not appear in the unprompted examples designed to prompt common features across all examples
- semi-specific prompts are a signal that merely points out that the prompted element is “unusual” in some way.
There is no prompt that is “correct.” A prompt serves a need. If it is constructed according to the appropriate procedures, it will serve the need.
When transitioning to unprompted examples:
- prompts that have been added to the example that do not appear in the unprompted example must be removed in one hit. If any part of the added prompt is still included, it can be used to respond to the example instead of relying on the features of the example.
- prompts that have transformed the example such that a feature of the unprompted example has been exaggerated or changed slightly but will still be part of the unprompted example can be faded back to the original state. Fade the transformation as quickly as possible in the least elaborate way.
- if the learner makes errors on unprompted examples, but responds appropriately to prompted examples, use a semi-specific prompt.
Manipulate the Emphasis
"Having students focus on just a few key portions of a task is a powerful tool for reducing intrinsic load, especially in the early stages of integrating a new skill into an existing process." That is, telling students "I won't worry about this, so you can focus on that." (Lovell, 2020, p54)
When a student knows what they need to do, just not how to do it or at the desired accuracy rate, we can use response-shaping by reinforcing on progressively better approximation responses to shape the response into the desired response (chapter 22).
Response shaping follows this process:
- Present nine trials to the learner. Provide encouragement to ensure that the learner is trying to produce the response.
- Carefully record the learner’s performance: notes or recording.
- Assign the responses to one of three groups.
- Non-reinforceable responses: worst three responses. During the initial shaping, you will not reinforce responses of this type. We do not punish the learner for non-reinforceable responses.
- Single-reinforceable responses: middle three responses. Responses of this type will receive single-reinforcement during initial shaping.
- Double-reinforcement responses: best three responses. Responses of this type receive double reinforcement.
- Present trials and reinforce responses according to the criteria above.
- Change the criterion for awarding the reinforcement when the learner receives reinforcement on about 90% of the trials by grouping the learner’s last nine trials into the three groups.
- Repeat the cycle of reassigning criteria for reinforcement each time the learner consistently receives reinforcement on about 90% of the trials. After three or four cycles, the learner is typically responding in the acceptable range.

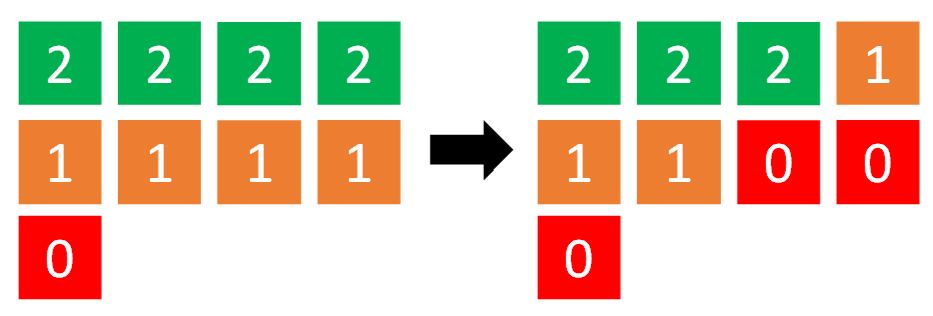
Chaining and Snowballing
Building up the individual atoms to the whole task requires connecting the atoms together. We can do this with forwards or backwards chaining or snowballing.
An expanded chain (chapter 24) centres around a physical operation consisting of various discriminations and motor responses related to that physical operation. The central operation is never fully covertised. Expanded programs (chapter 25) are to cognitive skills as expanded chains are to motor skills.
Teaching expanded chains is a variation of the three-level strategy for context-shaping.
The strategies for integrating the parts of a chain are:
Building up the individual atoms to the whole task requires connecting the atoms together. We can do this with forwards or backwards chaining or snowballing.
- Forwards chaining: "progressively building students' skills in the order in which they appear in the end product."
- Backwards chaining: "getting students to work through the different parts of the overall task, but working backwards from the last task in the sequence."
- Snowballing: "students complete the new segment, and all previous segments, each time."
- Semi-snowballing: completing a maximum of three or so components each time. (Lovell, 2020, p50-52)
An expanded chain (chapter 24) centres around a physical operation consisting of various discriminations and motor responses related to that physical operation. The central operation is never fully covertised. Expanded programs (chapter 25) are to cognitive skills as expanded chains are to motor skills.
Teaching expanded chains is a variation of the three-level strategy for context-shaping.
- Teach each skill within a juxtaposition pattern that permits rapid repetition of the skill.
Do not require the learner to complete the entire chain before practicing this behaviour. - Introduce the new skill into a small chain with several skills that occur with the new skill.
- Extend the chain when proficient, until the learner is performing the entire operation.
The strategies for integrating the parts of a chain are:
- unit integration (establish smaller chains that become juxtaposed units in larger chains) and
- trunk integration (establish a trunk that grows by single parts that are first taught in isolation)
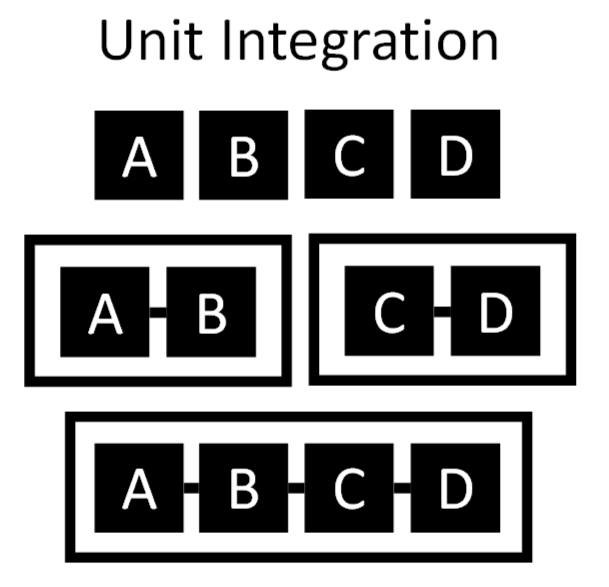
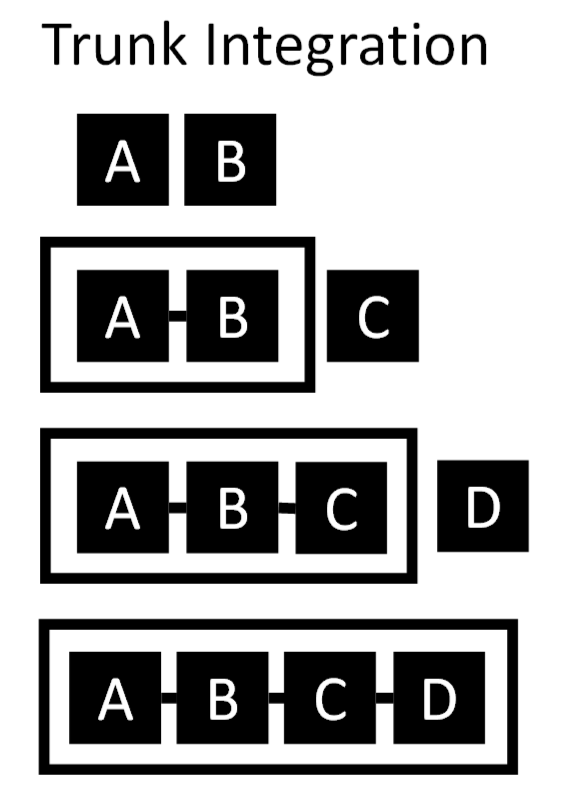
The following points should be kept in mind for expanded chains and programs:
Simplify the Conditions
"By simplifying the underlying task, students can rehearse the whole task while reducing intrinsic load." That is, "the learner is trained in the execution of all constituent skills at the same time, but the conditions under which the whole skill is trained change and gradually become more complex during the training." (Lovell, 2020, p53)
It is a mistake to think of physical operations as if the total operation is a sum of the various parts. It is not. A learner may not be able to perform on a removed component or part, but will perform the complex operation. We can reduce a task to a simpler form (chapter 22) so that it shares all the essential response features with all other examples of the response and contains as few component behaviours as any example of the response we can identify. The learner should focus solely on the simplified task and not other ancillary behaviours.
When simplifying the conditions we must keep in mind that:
The guiding principle is to design the program so the learner performs on fully detailed applications as quickly as possible. The program should contain the fewest possible steps—the sequence that is least elaborate. Three types of programs for simplifying conditions are (chapter 23):
Essential-response-features are essential to achieving the objective of the operation. The essential-response-features program starts in context with the learner only performing the features essential to the outcome and not the features that are required but not essential. The non-essential features are added in as the learner becomes proficient.
Enabling-response-features are not essential to achieving the objective of the operation, but occur in every instance of the operation. The enabling-response-features program starts in context with the learner only performing the features that are required but not essential and not the features essential to the outcome. The essential features are added in as the learner becomes proficient.
Parts are discontinuous if they can be executed in isolation outside the context of the operation without distortion.
They can be practised as units or steps that may later be chained together. The removed-component-behaviour program start in another context working on some part of the response that prevents the learner from performing correctly. We introduce the actual operation after achieving mastery on the removed part, possibly simplified.
That is, we pre-teach the discontinuous parts and simplify on continuous parts that can be produced only within the context of the operation or within a similar operation.
As a means of reducing extraneous load, we can fade worked examples of a problem from fully worked out, to partially worked out, to completely unworked by progressively omitting lines of working which students are required to complete themselves to bridge the gap between reading a worked example and completing a problem independently. We can omit lines in different ways:
Similar to essential- and enabling-response-features programs, we progressively make the student perform more of the process themselves, either focusing on the most difficult essential step, or the starting and ending enabling steps.
Conclusion
Hopefully this blogpost has helped you to connect a number of ideas from Theory of Instruction to some more well known ideas in Cognitive Load Theory. While not all ideas from both Theory of Instruction and Cognitive Load Theory have been covered (for example, modality and visual-spatial displays), I hope I've brought up ideas that may not be so well known from Theory of Instruction and made them, at least, a little bit more accessible.
If you want to read more about Engelmann's Theory of Instruction click here to read my summary of the book and click here to access the book itself.
References
Carnine, Doug & Engelmann, Siegfried (2016) Theory of Instruction: Principles and Applications.
Barbash, Shepard (2012) Clear Teaching: With Direct Instruction, Siegfried Engelmann Discovered a Better Way of Teaching. Education Consumers Foundation.
Lovell, Oliver (2020) Sweller's Cognitive Load Theory in Action. Melton: John Catt Educational Limited.
- Design the chain to be capable of processing all examples.
- Teach the pre-skills called for by that chain, schedule motor skills and applications of the entire operation early.
- The skill should first be taught in isolation and then integrated with the skills that have already been taught.
- Provide applications of the chain that permit the learner to do the same thing with juxtaposed examples.
- Examples range from easy to hard, we create stipulation if we adhere to a rigid, easy-to-hard sequence.
- Include early examples of all subtypes that present no great mechanical problems.
- Delay the presentation of highly irregular examples until the learner is firm on the other subtypes.
- Introduce irregulars using massed practice with the new type and integration with the other types that have been taught.
- Create sameness in responses to show how applications are the same.
- Reduce irrelevant details so the sameness is increased.
- Create rehearsal situations so that we can control the juxtapositions of the events.
- Introduce the application or transfer situations in which the skill is to be used.
- Shape the context by systematically introducing interruptions.
Simplify the Conditions
"By simplifying the underlying task, students can rehearse the whole task while reducing intrinsic load." That is, "the learner is trained in the execution of all constituent skills at the same time, but the conditions under which the whole skill is trained change and gradually become more complex during the training." (Lovell, 2020, p53)
It is a mistake to think of physical operations as if the total operation is a sum of the various parts. It is not. A learner may not be able to perform on a removed component or part, but will perform the complex operation. We can reduce a task to a simpler form (chapter 22) so that it shares all the essential response features with all other examples of the response and contains as few component behaviours as any example of the response we can identify. The learner should focus solely on the simplified task and not other ancillary behaviours.
When simplifying the conditions we must keep in mind that:
- If the communication presents examples with a very narrow range of differences, the communication may induce stipulation: the absence of some features implies that the response is not to be produced.
- If the communication presents examples that permit many response options, the communication may induce distortion: the performance on easier examples allows for methods that do not generalise to harder examples.
The guiding principle is to design the program so the learner performs on fully detailed applications as quickly as possible. The program should contain the fewest possible steps—the sequence that is least elaborate. Three types of programs for simplifying conditions are (chapter 23):
- the essential-response-features program
- the enabling-response-features program (or non-essential-features program)
- the removed-component-behaviour program
Essential-response-features are essential to achieving the objective of the operation. The essential-response-features program starts in context with the learner only performing the features essential to the outcome and not the features that are required but not essential. The non-essential features are added in as the learner becomes proficient.
Enabling-response-features are not essential to achieving the objective of the operation, but occur in every instance of the operation. The enabling-response-features program starts in context with the learner only performing the features that are required but not essential and not the features essential to the outcome. The essential features are added in as the learner becomes proficient.
Parts are discontinuous if they can be executed in isolation outside the context of the operation without distortion.
They can be practised as units or steps that may later be chained together. The removed-component-behaviour program start in another context working on some part of the response that prevents the learner from performing correctly. We introduce the actual operation after achieving mastery on the removed part, possibly simplified.
That is, we pre-teach the discontinuous parts and simplify on continuous parts that can be produced only within the context of the operation or within a similar operation.
As a means of reducing extraneous load, we can fade worked examples of a problem from fully worked out, to partially worked out, to completely unworked by progressively omitting lines of working which students are required to complete themselves to bridge the gap between reading a worked example and completing a problem independently. We can omit lines in different ways:
- Backward fading: "the first line omitted is the final line of the worked example", then successively fades the previous lines.
- Forward fading: the first line omitted is the first line of the worked example, then successively fades the next lines.
- Contour fading: the first line omitted is the most difficult line (the peak) of the worked example, then successively fades the previous and next line in both directions from the peak. (Lovell, 2020, p113)
Similar to essential- and enabling-response-features programs, we progressively make the student perform more of the process themselves, either focusing on the most difficult essential step, or the starting and ending enabling steps.
Conclusion
Hopefully this blogpost has helped you to connect a number of ideas from Theory of Instruction to some more well known ideas in Cognitive Load Theory. While not all ideas from both Theory of Instruction and Cognitive Load Theory have been covered (for example, modality and visual-spatial displays), I hope I've brought up ideas that may not be so well known from Theory of Instruction and made them, at least, a little bit more accessible.
If you want to read more about Engelmann's Theory of Instruction click here to read my summary of the book and click here to access the book itself.
References
Carnine, Doug & Engelmann, Siegfried (2016) Theory of Instruction: Principles and Applications.
Barbash, Shepard (2012) Clear Teaching: With Direct Instruction, Siegfried Engelmann Discovered a Better Way of Teaching. Education Consumers Foundation.
Lovell, Oliver (2020) Sweller's Cognitive Load Theory in Action. Melton: John Catt Educational Limited.
 RSS Feed
RSS Feed
